이번에 이 글을 작성하게 되는 이유는 위의 Android 공식 홈페이지의 기술되어 있는 부분들에 대해 코드 레벨에서 어떻게 동작이 되는지 확인 해보고 싶은 순수한 학구적인 욕구 때문입니다
SurfaceFlinger 및 WindowManager | Android 오픈소스 프로젝트 | Android Open Source Project
SurfaceFlinger 및 WindowManager | Android 오픈소스 프로젝트 | Android Open Source Project
SurfaceFlinger 및 WindowManager 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. SurfaceFlinger는 버퍼를 받아들이고 버퍼를 구성하며 버퍼를 디스플레이로 보냅니다. W
source.android.com
참고) 아래 나와 있는 코드들은 AOSP 코드 기준입니다
안드로이드에서 화면에 보이는 모든 것들은 프레임 버퍼들의 조합입니다
이 버퍼들은 소비(Consume), 생산(Produce) 해주는 두 측이 존재합니다
버퍼를 소비, 생산 해줄 때 ANativeWindow라는 껍데기에 렌더링을 해주는 식입니다
기존의 2D 안드로이드에서는 rendering을 해주는 엔진이 skia 엔진이었으나, 현재는 SkiaOpenGLPipeline, SkiaVulkanPipeline등의 네이밍을 쓰는 것으로 보아하니 skia + (openGL or vulkan) 이런 식으로 사용 되는 것 같습니다
그 중 이번에 볼 것은 queueBuffer이고 이것은 버퍼의 생산자 관점입니다
먼저 queueBuffer 메서드의 매핑이 어떻게 이루어지는 지 알아보려면, Surface.cpp 파일을 먼저 봐야합니다
(native/libs/gui/Surface.cpp)
queueBuffer 메서드 mapping
queueBuffer 매핑하는 과정도 크게 두 가지가 있는데
hwui를 이용하는 방법과 sw를 사용해서 렌더링 하는 과정으로 나뉩니다
hwui 사용 유무와 상관없이 결국은 Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd)를 호출합니다
1) hwui 사용시
// Surface 생성자
ANativeWindow::queueBuffer = hook_queueBuffer;
// Surface::hook_queueBuffer
int Surface::hook_queueBuffer(ANativeWindow* window,
ANativeWindowBuffer* buffer, int fenceFd) {
Surface* c = getSelf(window);
{
std::shared_lock<std::shared_mutex> lock(c->mInterceptorMutex);
if (c->mQueueInterceptor != nullptr) {
auto interceptor = c->mQueueInterceptor;
auto data = c->mQueueInterceptorData;
return interceptor(window, Surface::queueBufferInternal, data, buffer, fenceFd);
}
}
return c->queueBuffer(buffer, fenceFd); // hw 사용 안할 시에는 바로 이 부분을 탐
}ANativeWindow의 queueBuffer를 hook_queueBuffer로 mapping 해줍니다
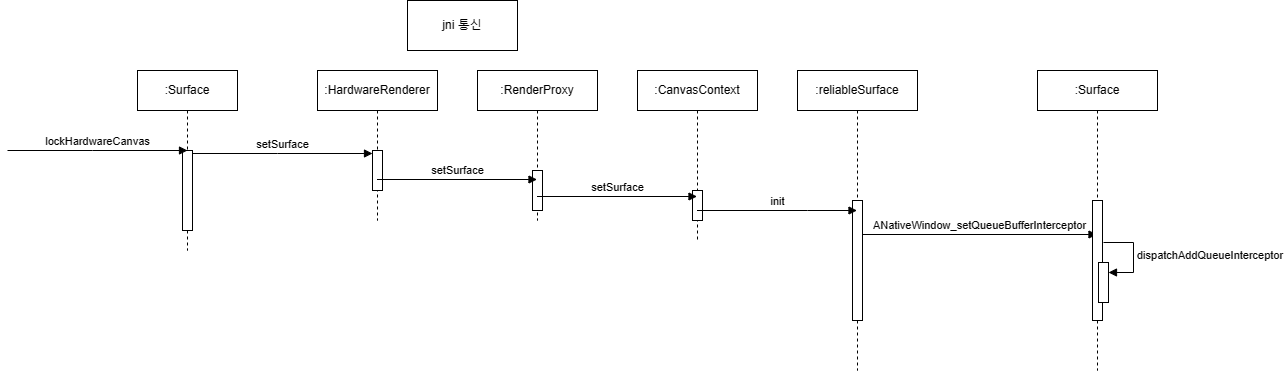
hardware canvas를 그리는 hwui에서는 mapping되는 메서드가 결국 ReliableSurface의 hook_queueBuffer 메서드입니다
// ReliableSurface::init
result = ANativeWindow_setQueueBufferInterceptor(mWindow, hook_queueBuffer, this);
// ReliatbleSurface::hook_queueBuffer
int ReliableSurface::hook_queueBuffer(ANativeWindow* window,
ANativeWindow_queueBufferFn queueBuffer, void* data,
ANativeWindowBuffer* buffer, int fenceFd) {
ReliableSurface* rs = reinterpret_cast<ReliableSurface*>(data);
rs->clearReservedBuffer();
if (rs->isFallbackBuffer(buffer)) {
if (fenceFd > 0) {
close(fenceFd);
}
return OK;
}
return queueBuffer(window, buffer, fenceFd);
}넘겨주는 ANativeWindow_queueBufferFn을 호출해주는 것이고, Suface::queueBufferInternal을 넘겨주는 것입니다
결국 queueBuffer(buffer, fenceFd)를 호출해주는 것은 동일합니다
// Surface::queueBufferInternal
int Surface::queueBufferInternal(ANativeWindow* window, ANativeWindowBuffer* buffer, int fenceFd) {
Surface* c = getSelf(window);
return c->queueBuffer(buffer, fenceFd);
}
// Surface::queueBuffer
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
...
int i = getSlotFromBufferLocked(buffer);
...
IGraphicBufferProducer::QueueBufferOutput output;
IGraphicBufferProducer::QueueBufferInput input;
getQueueBufferInputLocked(buffer, fenceFd, mTimestamp, &input);
sp<Fence> fence = input.fence;
nsecs_t now = systemTime();
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);
int Surface::getSlotFromBufferLocked(
android_native_buffer_t* buffer) const {
if (buffer == nullptr) {
ALOGE("%s: input buffer is null!", __FUNCTION__);
return BAD_VALUE;
}
for (int i = 0; i < NUM_BUFFER_SLOTS; i++) {
if (mSlots[i].buffer != nullptr &&
mSlots[i].buffer->handle == buffer->handle) {
return i;
}
}
ALOGE("%s: unknown buffer: %p", __FUNCTION__, buffer->handle);
return BAD_VALUE;
}getSlotFromBufferLocked를 통해, 지금 buffer가 비어있는 slot의 index를 넘겨줍니다
// surface.h
protected:
enum { NUM_BUFFER_SLOTS = BufferQueueDefs::NUM_BUFFER_SLOTS };
// BufferQueueDefs.h
namespace BufferQueueDefs {
// BufferQueue will keep track of at most this value of buffers.
// Attempts at runtime to increase the number of buffers past this
// will fail.
static constexpr int NUM_BUFFER_SLOTS = 64;buffer slot의 개수는 찾아보니 64개로 되어 있습니다
다시 위의 코드 부분으로 돌아가서 queueBuffer 메서드를 보면 GraphicBufferProducer의 queueBuffer를 호출해줍니다
GraphicBufferProducer의 관계를 보기 위해 아래 클래스 다이어 그램을 확인해보겠습니다

여기서 알아야 하는 건 BLASTBufferItemQueue가 ConsumerBase의 FrameAvaliableListener의 구현체라는 것입니다
queueBuffer sequence
1) SyncAndDrawFrame 경로
그래픽 버퍼는 surface(ANativeWindow)에 dequeueBuffer를 통해 버퍼를 담을 그릇을 받고,
rendering 된 결과를 queueBuffer를 통해 넣어주면 FrameAvailable 리스너를 호출해서 실제적으로 소비자가 넣어진 버퍼를 받아서 화면에 보여주게 됩니다
기존의 안드로이드 2d 렌더링 엔진은 skia 엔진을 사용했으나 현재는 OpenGL, Vulkan등의 엔진과 함께 사용하는 것으로 보입니다 (네이밍도 SkiaOpenGLPipeline, SkiaVulkanPipeline으로 사용하는 것으로 보여서)
아래 sequence diagram은 RenderProxy의 syncAndDrawFrame이 불릴 때, vulkan의 pipeline을 사용하여 rendering을 해주는 부분입니다

참고) Pipeline의 결정 로직
// RenderProxy.cpp
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode,
IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance()), mContext(nullptr) {
mContext = mRenderThread.queue().runSync([&]() -> CanvasContext* {
return CanvasContext::create(mRenderThread, translucent, rootRenderNode, contextFactory);
});
// CanvasContext.cpp
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent,
RenderNode* rootRenderNode, IContextFactory* contextFactory) {
auto renderType = Properties::getRenderPipelineType();
switch (renderType) {
case RenderPipelineType::SkiaGL:
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique<skiapipeline::SkiaOpenGLPipeline>(thread));
case RenderPipelineType::SkiaVulkan:
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique<skiapipeline::SkiaVulkanPipeline>(thread));ThreadedRenderer가 create될 때 Java 코드 <-> native 코드 (c 단) 통신을 위해 renderProxy가 생성되고
RenderProxy 생성 때 GL, Vulkan pipeline이 결정이 됩니다
2) queueBuffer를 호출 한 후

위에서 설명드렸듯, queueBuffer를 통해 buffer가 채워지면 FrameAvailable가 호출 되고
만일 NextTranactionSet이 설정 되어 있는 경우 buffer를 acquire해가게 됩니다
'안드로이드 > 안드로이드 프레임워크' 카테고리의 다른 글
| 안드로이드 미디어 프레임워크(SurfaceFlinger) 학습 3 (3) | 2024.02.27 |
|---|---|
| 안드로이드 미디어 프레임워크(SurfaceFlinger) 학습 2 (2) | 2024.02.25 |
| 안드로이드에서 Zygote가 실행되는 순서 2 (1) | 2022.05.15 |
| 안드로이드에서 Zygote가 실행되는 순서 1 (2) | 2022.05.13 |
| Android framework StartActivity 호출 순서 (2) | 2022.05.09 |